Blog

Beyond Apollo Federation - How to use Composite Schemas and Extensions to integrate non-GraphQL data sources
Integrate non-GraphQL data sources like REST APIs and gRPC services with Composite Schemas as Grafbase Extensions

Announcing OAuth 2.1 support in the Grafbase MCP server
Introducing full OAuth support in the MCP server, enabling secure authentication and authorization for your applications.
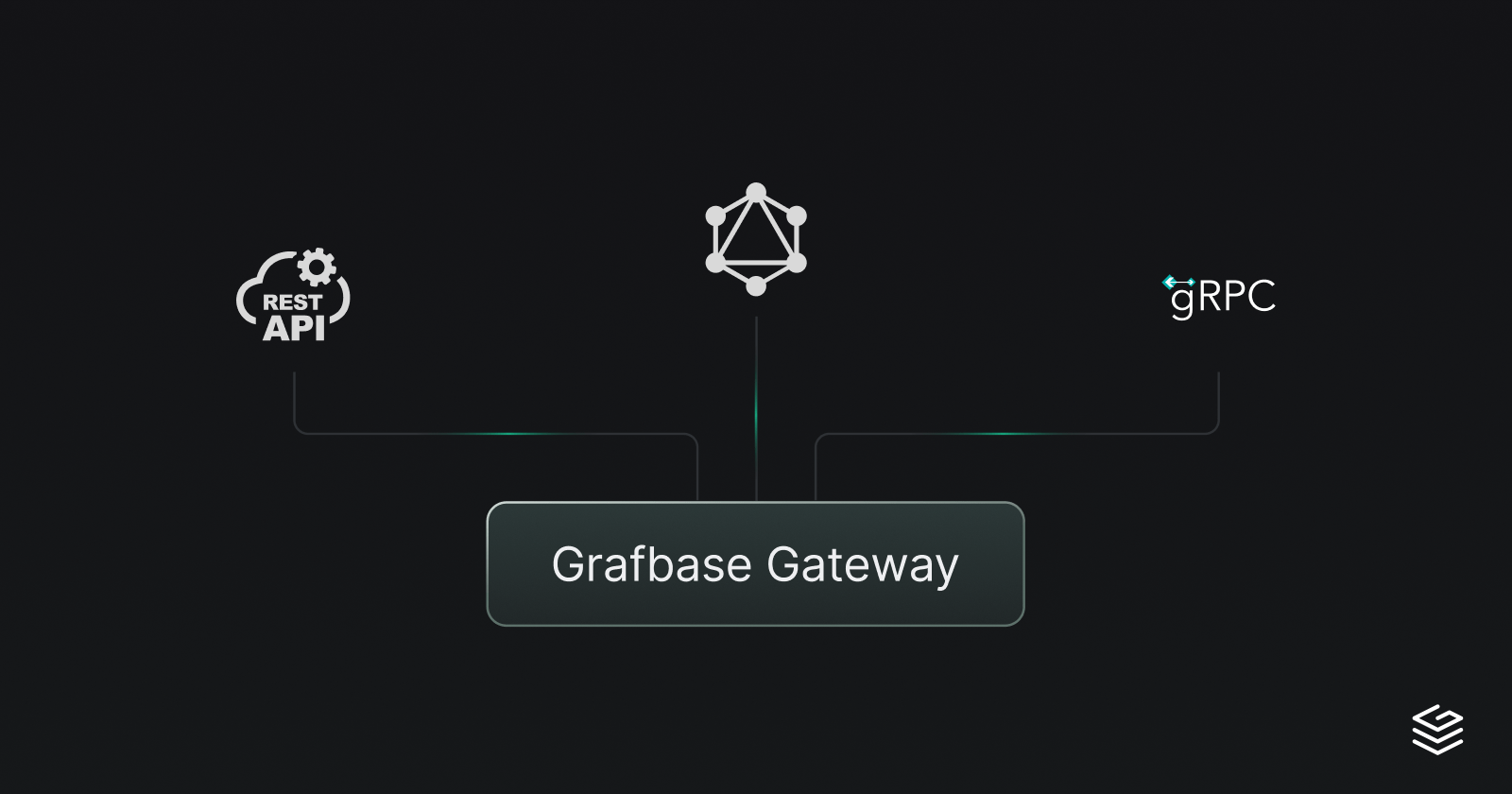
Extend REST and gRPC APIs with GraphQL using Grafbase
Learn how to expose gRPC and REST services as GraphQL subgraphs using Grafbase without rewriting or proxying your existing systems.

What are MCP Servers and how does Grafbase support them?
Learn how MCP servers enable AI models to access real-time data directly through GraphQL APIs, and discover how Grafbase enables scalable MCP-ready architectures.
Building for speed: How GraphQL Federation enables high-velocity teams
Learn how GraphQL Federation removes team coordination bottlenecks, enabling faster delivery by decentralizing schema ownership while maintaining a unified API. Discover how this approach increases team autonomy and accelerates product development.

Grafbase Extensions now power federated GraphQL APIs with Kafka
Integrate Apache Kafka directly into your federated GraphQL API with zero infrastructure management - no subgraphs, no manual stitching, and no extra services required.

The Lifecycle of a Federated GraphQL API, from Chaos to Coherence
The Lifecycle of a Federated GraphQL API, from Chaos to Coherence
Why GraphQL is eating the API world
Why GraphQL is eating the API world
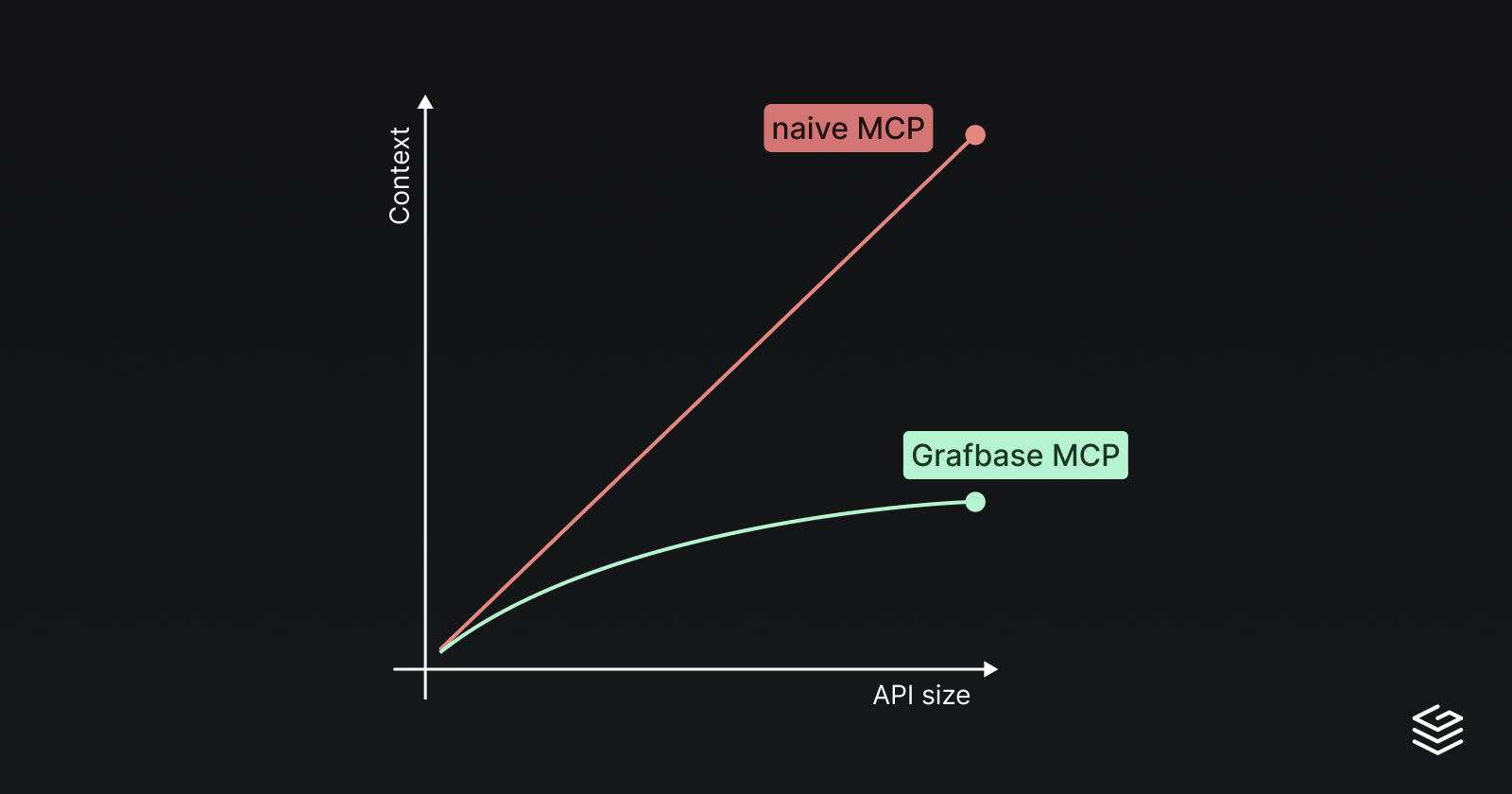
Solving context explosion in GraphQL MCP servers
Expose complex GraphQL APIs without bloating the context with the full schema

Grafbase achieves SOC 2 Type II compliance
We’re pleased to announce that Grafbase has successfully achieved SOC 2 Type II compliance, an important milestone in our ongoing commitment to trust, security, and operational excellence.

Why self-host Grafbase? Benefits of deploying the Grafbase Enterprise Platform in your own environment
Explore the benefits of self-hosting Grafbase Enterprise Platform for data residency compliance, infrastructure control, security integration, and deployment flexibility. Learn when self-hosting makes sense for your organization versus using the managed service.

Grafbase Extensions now power Federated GraphQL APIs with Postgres
Integrate PostgreSQL databases directly into your federated GraphQL API with zero infrastructure management - no subgraphs, no manual stitching, and no extra services required.